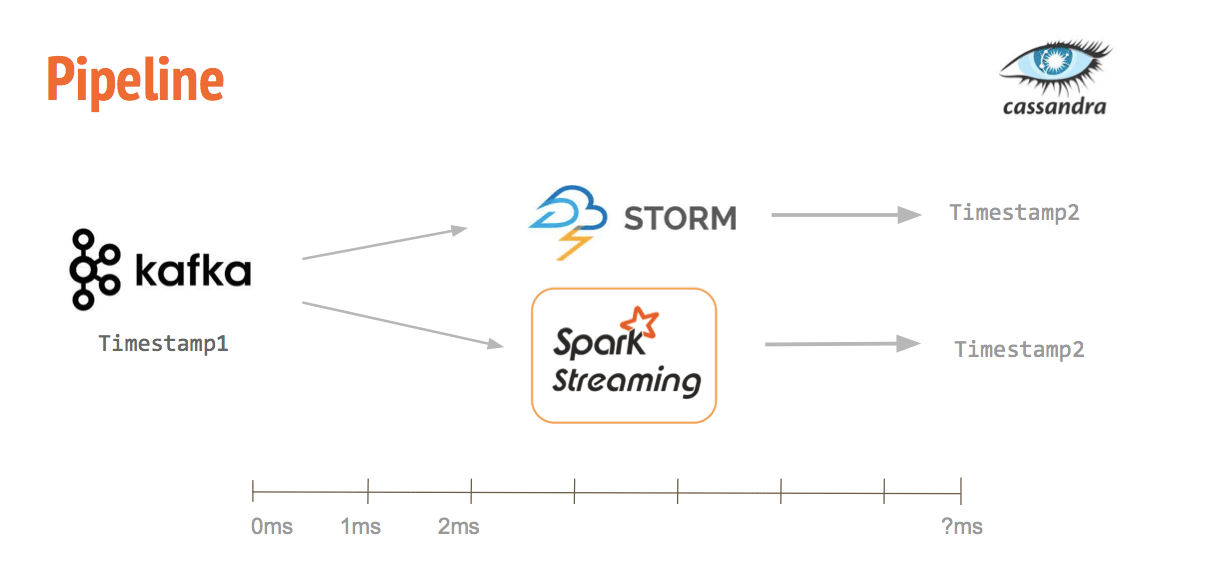
I’m using Kafka-Python and PySpark to work with the Kafka + Spark Streaming + Cassandra pipeline completely in Python rather than with Java or Scala. Completely my choice because I aim to present this for NYC PyLadies, and potentially other Python audiences. This combination of software KSSC is one of the two streams for my comparison project, the other uses Storm and I’ll denote as KSC.
First things first - you have to start your stream before you can ingest data to the pipeline…
spark-submit --packages org.apache.spark:spark-streaming-kafka_2.10:1.5.0,TargetHolding/pyspark-cassandra:0.1.5 --conf spark.cassandra.connection.host=127.0.0.1 example.py my-topic
Notice the --packages flag adding JAR dependencies and the --conf flag pointing to the Cassandra cluster. These jar files are needed since we aren’t rewriting them in Python.
Here’s how my Cassandra table looks like:
select * from test1 limit 5;
testid| time1 | delta | time2
-------+----------------------------+--------+----------------------------
KSSC | 2015-09-30 03:04:14.914881 | 217504 | 2015-10-01 23:20:59.697377
KSSC | 2015-09-30 03:04:14.914109 | 216732 | 2015-10-01 23:20:59.697377
KSSC | 2015-09-30 03:04:14.913434 | 216057 | 2015-10-01 23:20:59.697377
KSSC | 2015-09-30 03:04:14.912704 | 215327 | 2015-10-01 23:20:59.697377
KSSC | 2015-09-30 03:04:14.911870 | 214493 | 2015-10-01 23:20:59.697377
CREATE TABLE test1 (testid text, date text, time1 timestamp, time2 timestamp, PRIMARY KEY ((id, date), time1), ) WITH CLUSTERING ORDER BY (time1 DESC);
The code for streaming is very much like the example presented in this example (link)
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import pyspark_cassandra
from pyspark_cassandra import streaming
from datetime import datetime
# Create a StreamingContext with batch interval of 3 second
sc = SparkContext("spark://MASTER:7077", "myAppName")
ssc = StreamingContext(sc, 3)
topic = "my-topic"
kafkaStream = KafkaUtils.createStream(ssc, "MASTER_IP:2181", "topic", {topic: 4})
raw = kafkaStream.flatMap(lambda kafkaS: [kafkaS])
time_now = datetime.utcnow().strftime('%Y-%m-%d %H:%M:%S.%f')
clean = raw.map(lambda xs: xs[1].split(","))
# Match cassandra table fields with dictionary keys
# this reads input of format: x[partition, timestamp]
my_row = clean.map(lambda x: {
"testid": "test",
"time1": x[1],
"time2": time_now,
"delta": (datetime.strptime(x[1], '%Y-%m-%d %H:%M:%S.%f') -
datetime.strptime(time_now, '%Y-%m-%d %H:%M:%S.%f')).microseconds,
})
# save to cassandra
my_row.saveToCassandra("KEYSPACE", "TABLE_NAME")
ssc.start() # Start the computation
ssc.awaitTermination() # Wait for the computation to terminate
And of course I instagram the waiting period while testing the stream to help time pass by.