first impressions with scrapy for web scraping
Tonight I had some time to try out web scraping for the fragrance project that I’ve been thinking about pursuing for a while. I used a popular Python library called Scrapy because I’ve heard about it being used by a wide number of colleagues over years, and also I’ve met one of the core contributors in the past. I wanted to see what it’s like, whether I could get it running tonight.
Earlier tonight at about 9:15pm, after finishing dinner of a splendid authentic freshly cooked taco dinner ![]() from up the street, I sat down in front of the computer with a slice of chocolate cake
from up the street, I sat down in front of the computer with a slice of chocolate cake ![]() decided it was the night to try collecting data. Nothing like having a happy belly for a focused session of coding.
decided it was the night to try collecting data. Nothing like having a happy belly for a focused session of coding.
Wondered how it went? In less than 2 hours, despite bumping into almost any imaginable issue in getting set up, I was able to install and scrape one page to find out that Dolce & Gabbana retail 66 different perfumes worldwide. Looking more into their history, the company was founded in 1985 by two Italian designers to create leotards and now sell all sorts of products including, clothing, footwear, handbags, sunglasses, watches, jewellery, perfumery and cosmetics. They launched their first perfume in 1992[1], which was awarded the Perfume Academy’s 1993 award for best feminine fragrance of the year.
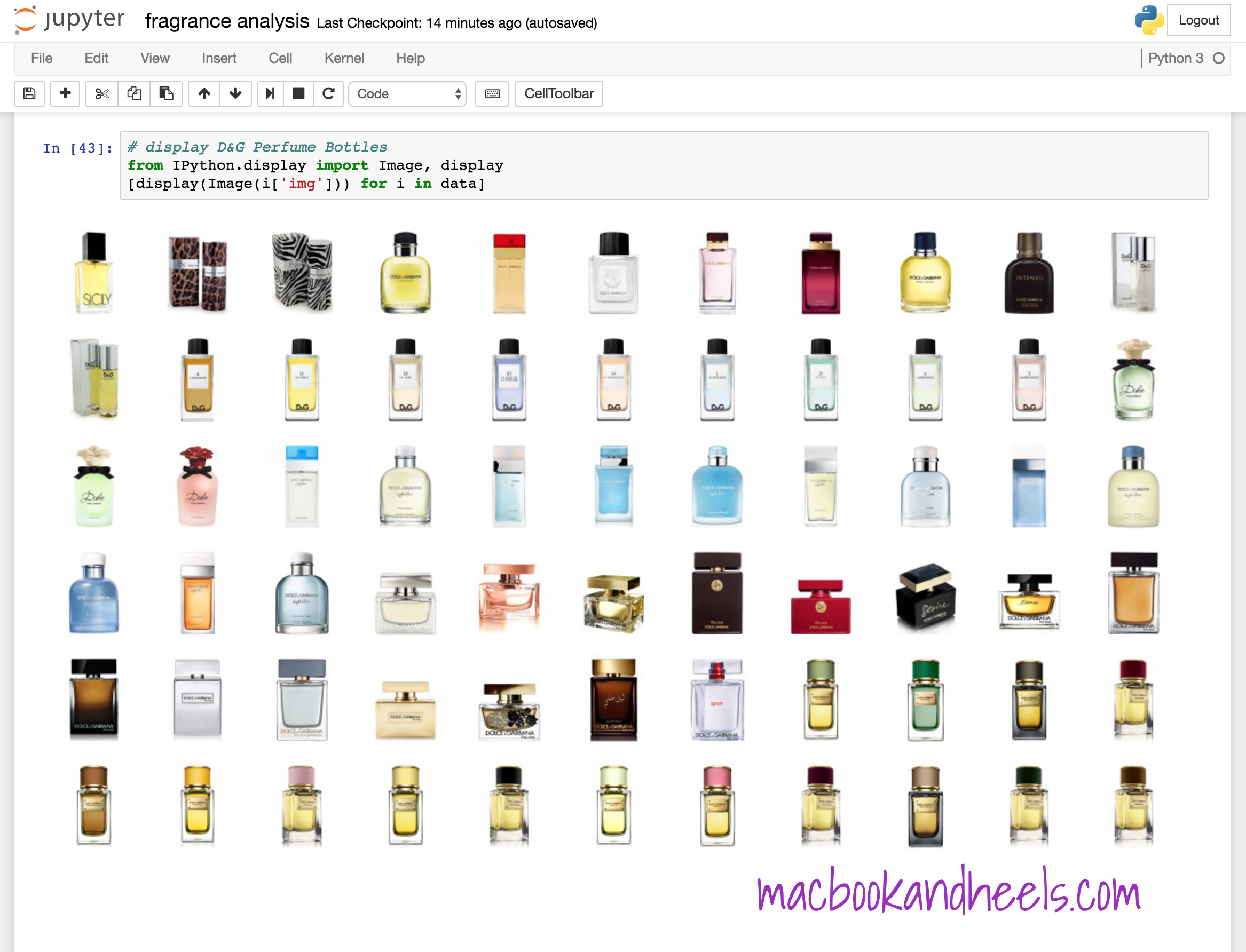
Table of Contents
1. Installing Scrapy
The main thing to remember with installing Python packages is that you can use pip:
pip install scrapy
It installed successfully on my machine with the use sudo, which I surmised after seeing permission error messages. Tried following the instructions in a tutorial as it promised thru a quick skim to work with jupyter, and tried the scrapy shell command.
scrapy shell "http://url/to/page/of/interest"
![]() It didn’t work!
It didn’t work! ![]()
Error messages about AttributeError: 'module' object has no attribute 'OP_NO_TLSv1_1' … after googling for a minute and trying various tips offered by the friendly pythonistas on the interwebs, I realized the silly oopsies mistake that could only happen by being absent from Python-ing on my laptop the last couple of months. My environment is set up so that the default Python version is v3, and I used pip which is linked to Python v2. pip3 is linked to Python v3 so that should have been used. I reinstalled scrapy with pip3 and it worked great.
These were the exact libraries I installed for compatibility with Python3:
pip3 install scrapy pyopenssl 'twisted[tls]'
After this, running the scrapy shell command scrapy shell "http://url/to/page/of/interest" worked great. I could then navigate thru the nodes with xpath.
Fig 1. Entering into the Scrapy Shell 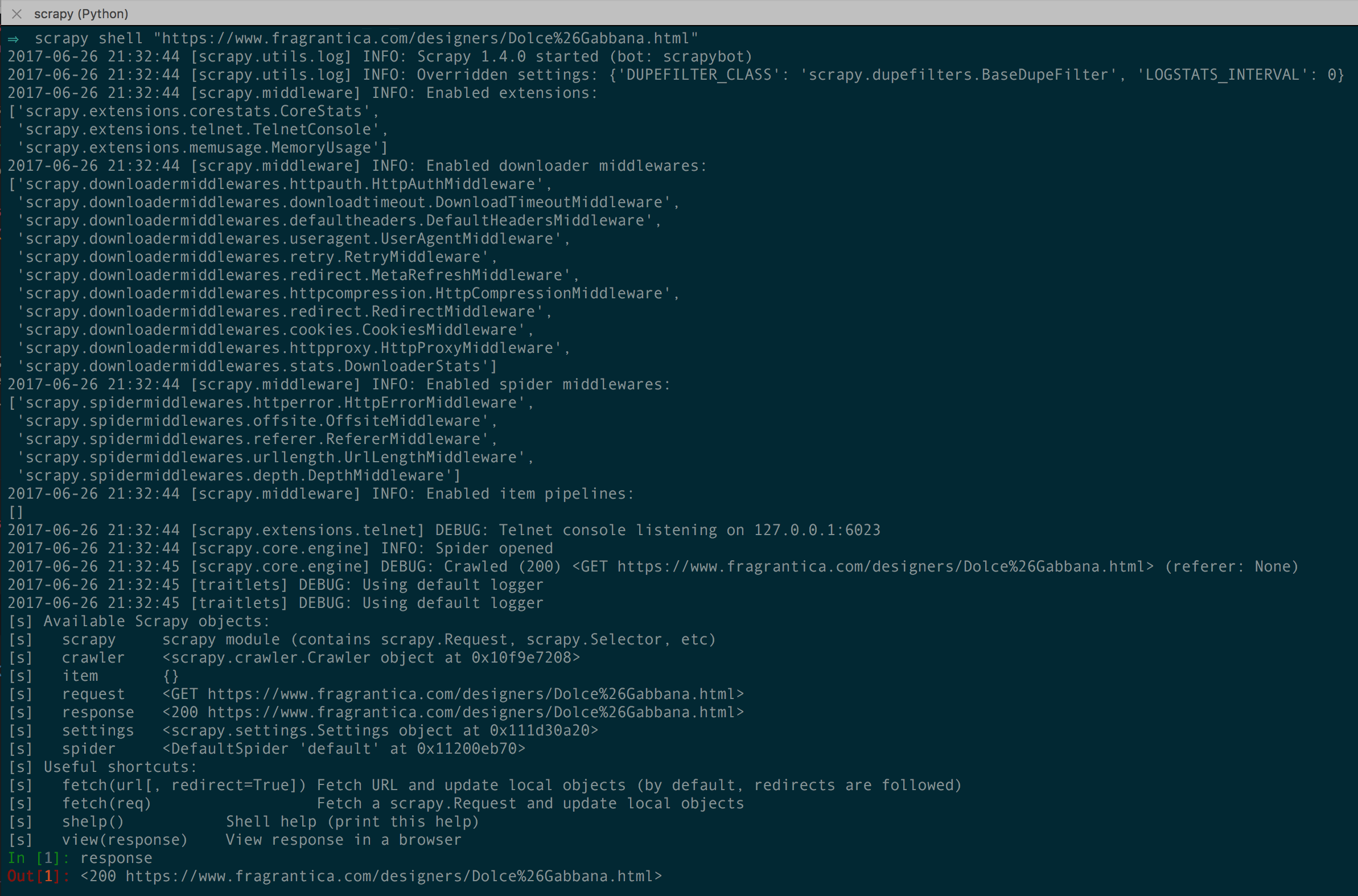
Fig 2. Navigating the xpath structure 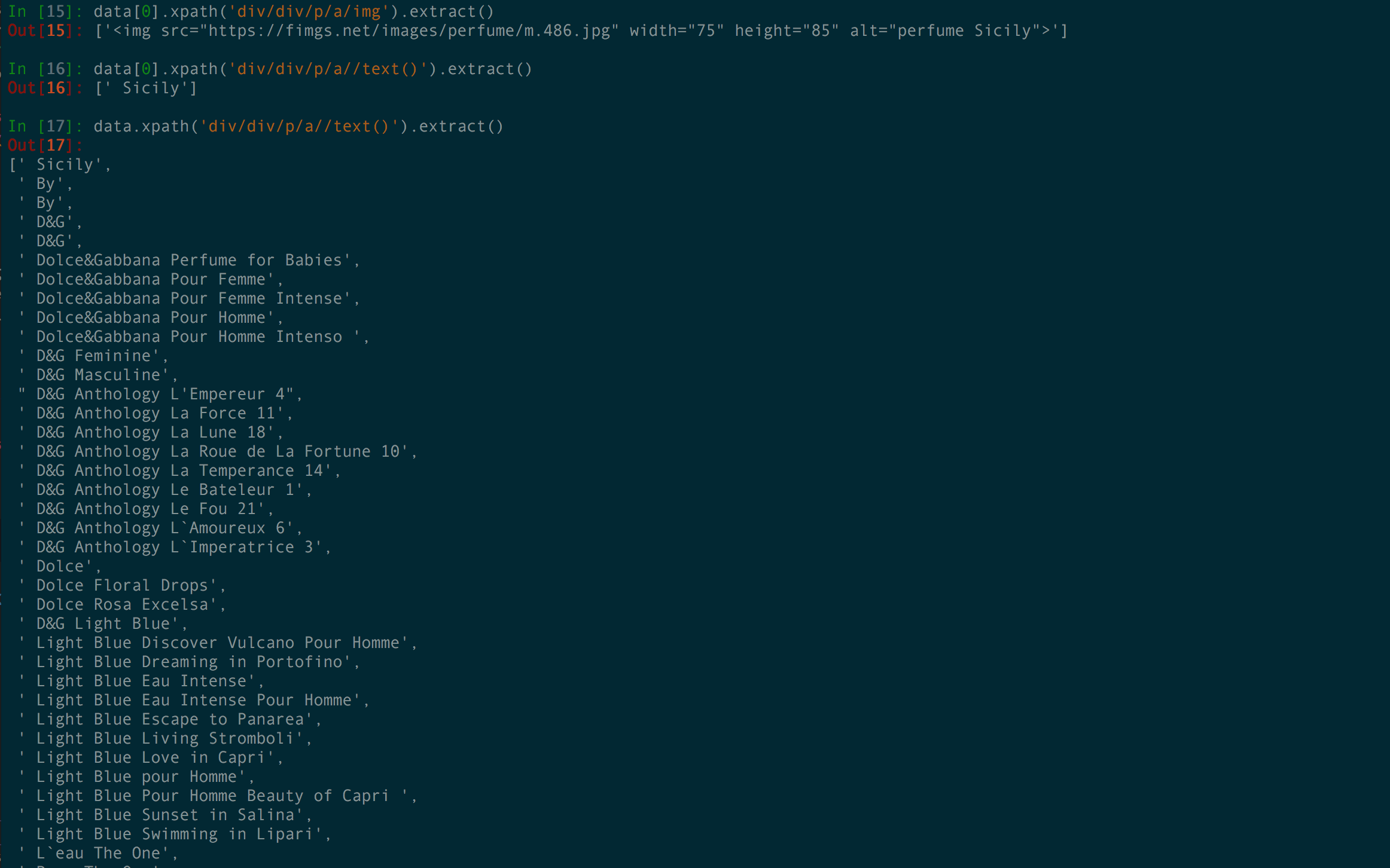
For the above screenshots, I am using iTerm with solarized theme
Conclusion about installation: easy, and fairly quick solving of the issue as it was my fault and not the installer.
2. Making requests to a website
I’m using requests because this is what I found to work, found it in an answer on StackOverflow.
import requests
from scrapy.http import TextResponse
When making the requests, you want to make sure to supply the user agent string to mimic the use of viewing the page with a browser. Here I am defining the url to be the Dolce & Gabbana products page that lists all the D&G perfumes.
url = "https://www.fragrantica.com/designers/Dolce%26Gabbana.html"
user_agent = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/58: .0.3029.110 Chrome/58.0.3029.110 Safari/537.36'}
r = requests.get(url, headers=user_agent)
response2 = TextResponse(r.url, body=r.text, encoding='utf-8')
Then I can grab the text values from the entire page source code by scanning the list in the middle of the page and printing the results:
c = response2.xpath('//div[@id="col1"]/div[@class="perfumeslist"]/div/div/p/a//text()').extract()
print("There are {} perfumes from Dolce & Gabbana".format(len(c)))
Now I know: There are 66 perfumes from Dolce & Gabbana
c = [' Sicily', ' By', ' By', ' D&G', ' D&G', ' Dolce&Gabbana Perfume for Babies', ' Dolce&Gabbana Pour Femme', ' Dolce&Gabbana Pour Femme Intense', ' Dolce&Gabbana Pour Homme', ' Dolce&Gabbana Pour Homme Intenso ', ' D&G Feminine', ' D&G Masculine', " D&G Anthology L'Empereur 4", ' D&G Anthology La Force 11', ' D&G Anthology La Lune 18', ' D&G Anthology La Roue de La Fortune 10', ' D&G Anthology La Temperance 14', ' D&G Anthology Le Bateleur 1', ' D&G Anthology Le Fou 21', ' D&G Anthology L`Amoureux 6', ' D&G Anthology L`Imperatrice 3', ' Dolce', ' Dolce Floral Drops', ' Dolce Rosa Excelsa', ' D&G Light Blue', ' Light Blue Discover Vulcano Pour Homme', ' Light Blue Dreaming in Portofino', ' Light Blue Eau Intense', ' Light Blue Eau Intense Pour Homme', ' Light Blue Escape to Panarea', ' Light Blue Living Stromboli', ' Light Blue Love in Capri', ' Light Blue pour Homme', ' Light Blue Pour Homme Beauty of Capri ', ' Light Blue Sunset in Salina', ' Light Blue Swimming in Lipari', ' L`eau The One', ' Rose The One', ' The One', ' The One Collector For Men', ' The One Collector For Women', ' The One Desire', ' The One Essence', ' The One for Men', ' The One for Men Eau de Parfum', ' The One for Men Platinum Limited Edition', ' The One Gentleman', ' The One Gold Limited Edition', ' The One Lace Edition', ' The One Royal Night', ' The One Sport', ' Velvet Bergamot', ' Velvet Cypress', ' Velvet Desert Oud', ' Velvet Desire', ' Velvet Exotic Leather', ' Velvet Ginestra', ' Velvet Love', ' Velvet Mimosa Bloom', ' Velvet Patchouli', ' Velvet Pure', ' Velvet Rose', ' Velvet Sublime', ' Velvet Tender Oud', ' Velvet Vetiver', ' Velvet Wood']
Thoughts: While I wanted to use the Jupyter notebook to capture data, there weren’t any obvious examples showing this particular use case. Translating the scrapy shell commands to work in the notebook was thus not obvious. I found an answer that was pretty close with using requests, but it kept giving me a 403 forbidden error. After chatting to a friend, it turns out that a user-agent string should be added to the header of requests to mimic reading by a browser.
Fig 3. Making requests in Jupyter 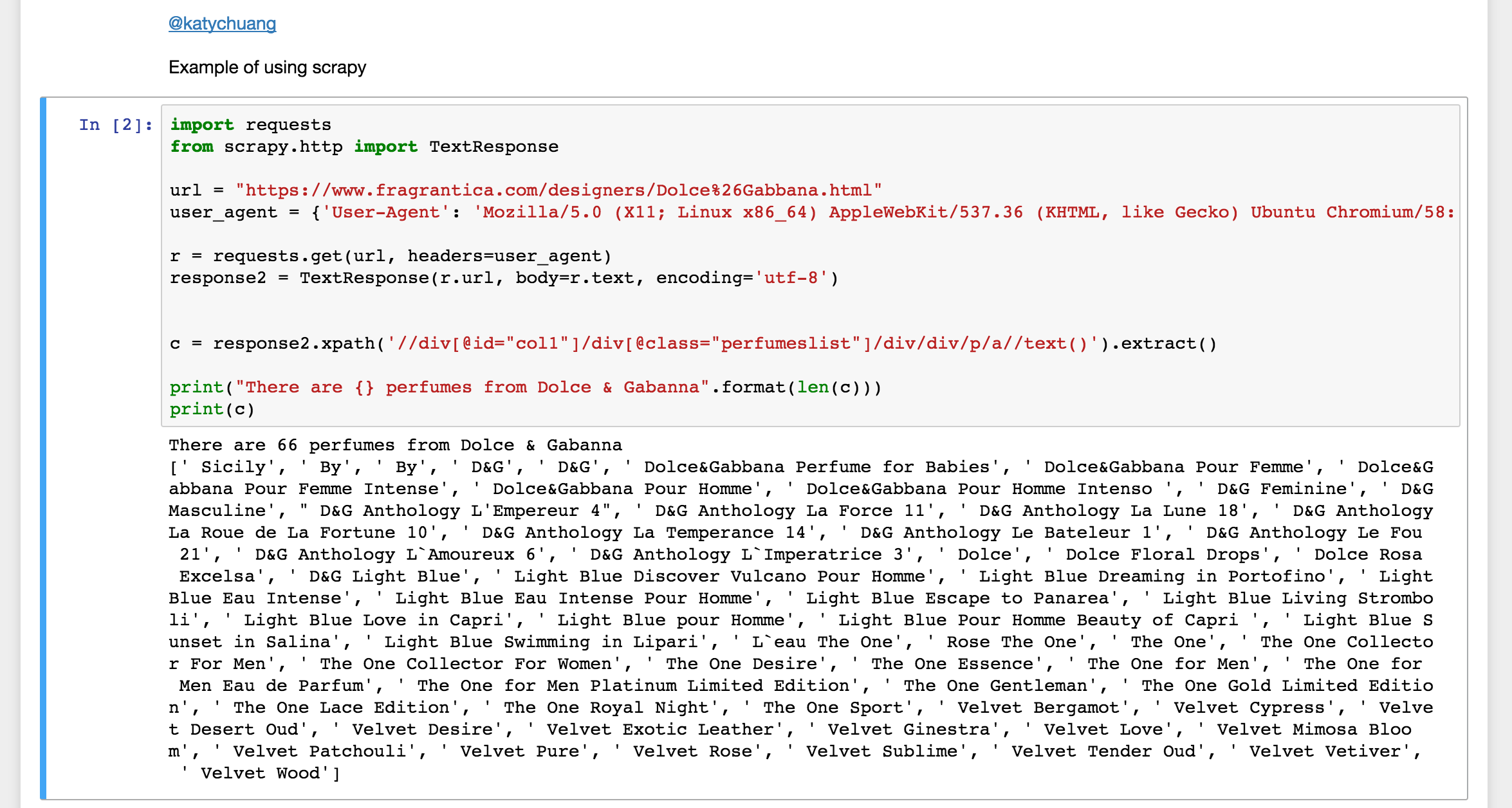
The documentation was decently easy to read with quick skims and easily found tutorials were easy to follow but their examples were not helpful for me to automatically make the jump to make requests thru the Jupyter notebook. Once it was figured out, it was very easy.
3. XPath options
Reading the available selector examples helped me figure out how to get either the attribute or text of HTML nodes.
- returning a list of Selector objects (ie. a SelectorList object):
sel.xpath("//h1") - returning a list of unicode strings:
sel.xpath("//h1").extract() # this includes the h1 tag sel.xpath("//h1/text()").extract() # this excludes the h1 tag - iterate over all <p> tags and print their class attribute:
sel.xpath("//p@class").extract()
Thus, continuing on, I could find out the breakdown of products by gender. First I parse the list, to make a list of dictionaries of product information.
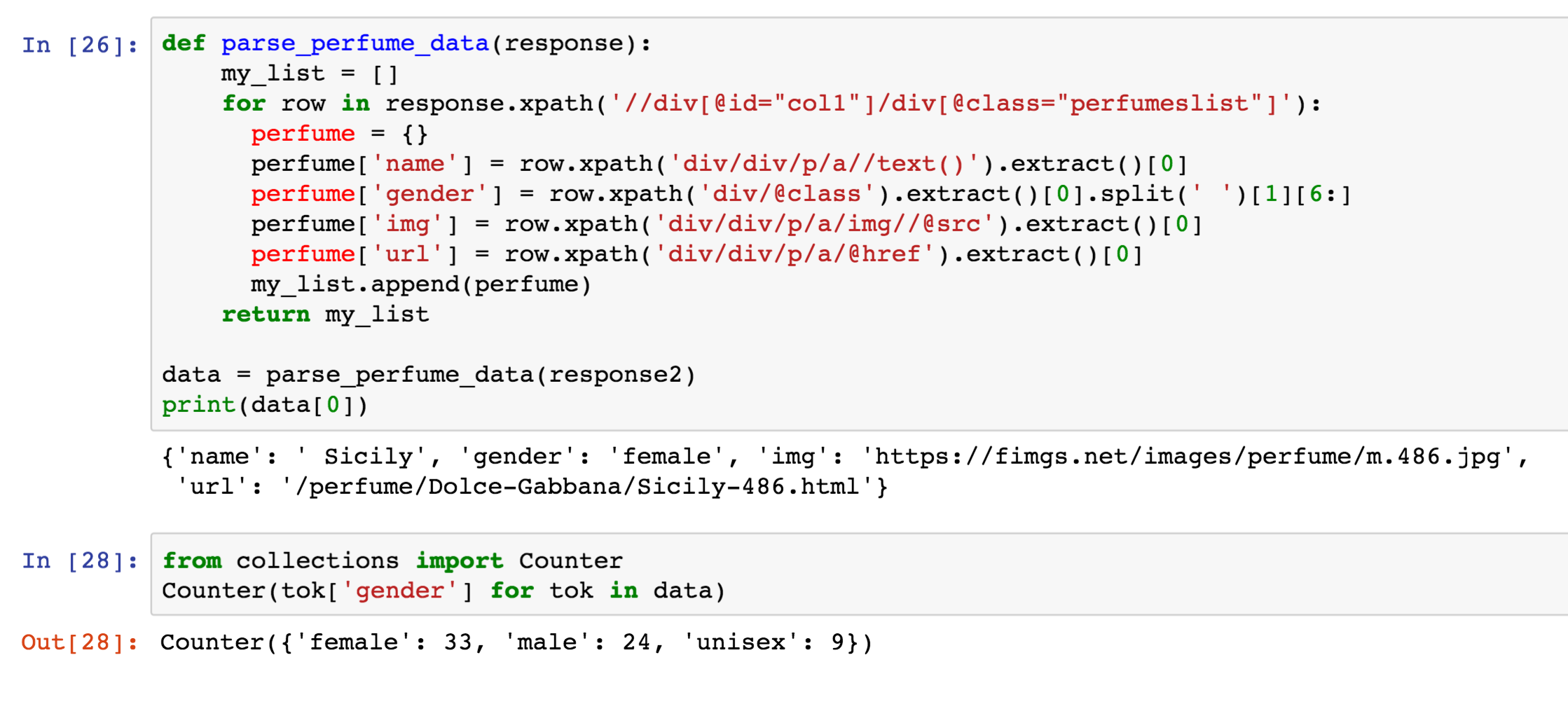
With that, I could easily group by gender to see how many products for each.
In: from collections import Counter
Counter(token['gender'] for token in data)
Out: Counter({'female': 33, 'male': 24, 'unisex': 9})
Conclusion: with the examples given, it was easy to figure out how to tailor the syntax to fix my particular use cases.
Tada! Printing images to the screen to show all the beautiful bottles ![]()
Final Code
The code is available as a jupyter notebook: fragrance analysis - scrapy example in my repo katychuang/jupyter-notebooks
~
Notes: Looking at the clock again, it appears that it took longer to write up this blog post and include screenshots and code samples than it did to write up the few lines of code to scrape the data. Wow! it’s a lot of work to be a blogger ![]()
[1]: “In 1992, the same year that they presented their men’s collection, they also launched their first perfume Dolce & Gabbana. They won the Woolmark award in 1991, and Perfume’s Academy “Most Feminine Flavor of the Year” in 1993 for their fragrance Dolce & Gabbana Parfum.” (-Wikipedia)