This post is still a work in progress
Two basic charts showing the results of comparisons. I showed these two charts during presentations today.
In case you missed earlier posts, I’m comparing Apache Storm (Trident) with Spark Streaming. They’re very similar in a lot of ways, yet one thing makes them different. Scroll down to see what makes them different.

These criteria makes it difficult to distinguish why they are different. What makes one a better choice than another for your pipeline? I aim to investigate further with a simple test of drawing squiggly lines.
Approach
I used the two pipelines with the setup described in earlier posts (link forthcoming), with Python drivers. Timestamps are recorded during ingestion and at the end of streaming, to show how long it takes messages to pass through.
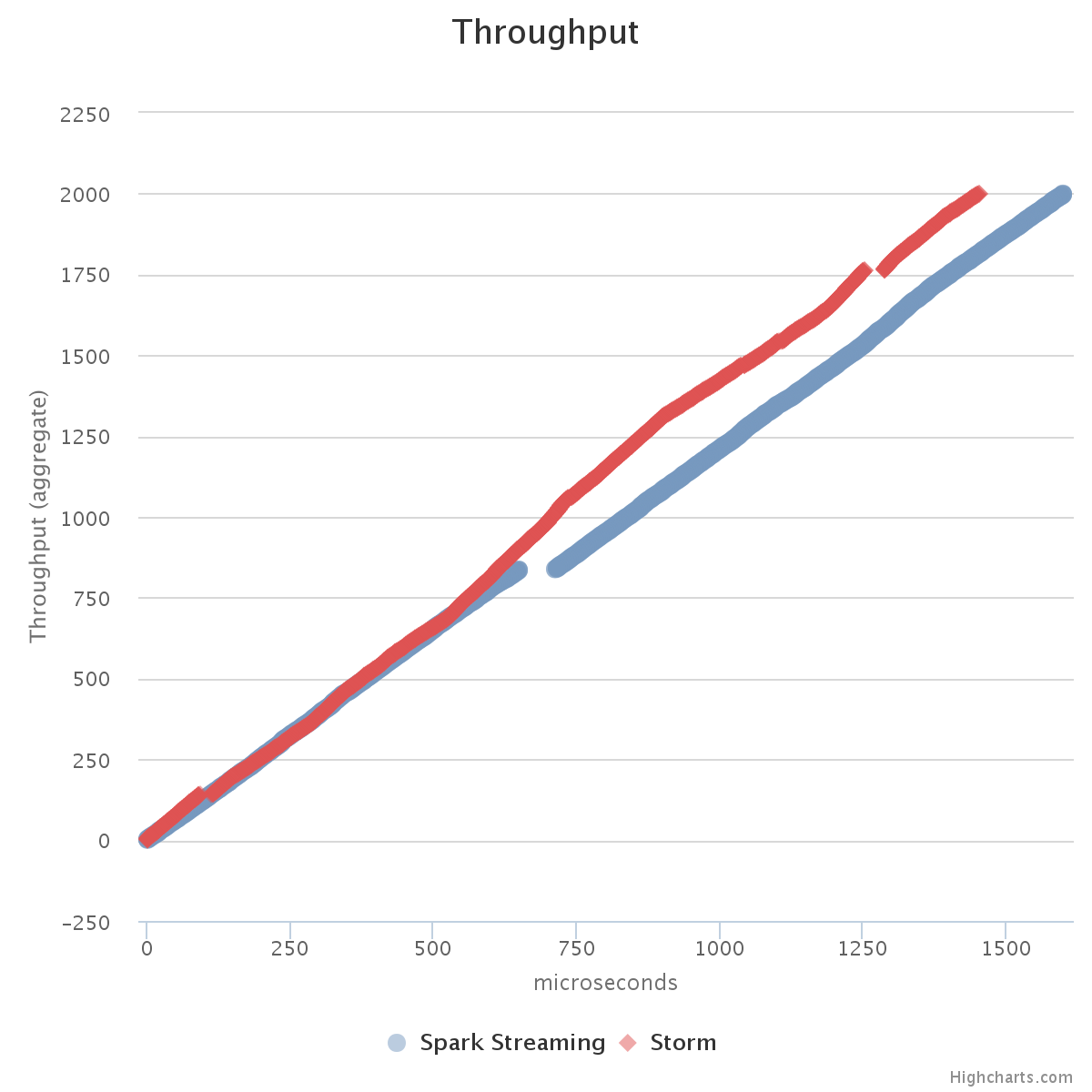
1. How many messages pass through the pipeline?
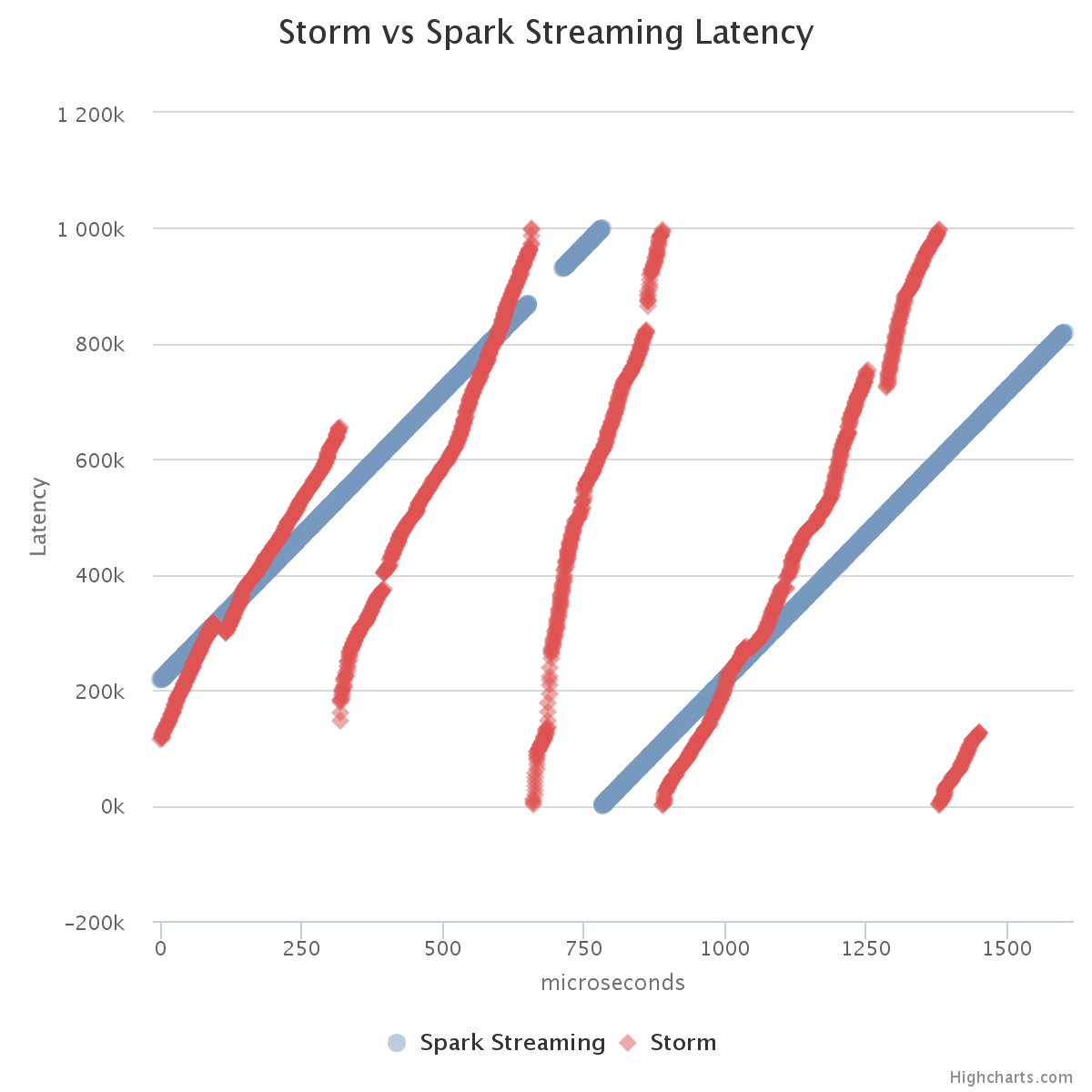
2. How long does it take for messages to pass through the pipeline?
Now for differences. This is where performance greatly differs - one does task parallel computation whereas the other does data-parallel computation.